Mind
I wanted to write up some of what I’ve been working on in my spare time. I’m doing this for a number of reasons: part reflection, part record, part catharsis.
Earlier this year I read The Mind is Flat by Nick Chater. It is an absolutely fantastic book that completely changed my view of human consciousness. I would thoroughly recommend it to anyone interested in the human mind.
In The Mind is Flat, Chater talks about the differing capabilities of modern computation and the mind. These mostly boil down the mind being exceptional at large, imaginative connections that can access completely disparate portions of knowledge whilst computers excel at standardised tasks.
The relationship between tools and the mind
He sees future advances as enhancing this relationship, just as past advances in the agricultural and industrial revolution helped to move us on, but played on the strengths of each of the parts. I agree that this connection could be very valuable, and this leads me to think about some of the most useful cases that I can imagine.
One of the first connections my own mind made is the link to The Extended Mind. Could we use personal computers (i.e. phones and smart wearables) as an effective extended mind?
In many ways we already do. Wikipedia is an excellent example of this and can be accessed by pretty much anyone at any time, anywhere. Other productivity tools (especially GSuite and its contenders) allow us to look up information on the fly. What we lack, however, is the tools that enhance the relationship between computer and mind; instead choosing to replace functions that the mind is often poor at and act as a crutch. Can we use these computing tools to prompt and elevate the mind in a way that could produce even better results than it already can?
What would this look like?
One of the most amazing things that our minds can do is to draw connections between seemingly disparate ideas. Not just creating random connections, but connections with meaning.
After having a little think about this, it seemed clear that one way to enhance this function to form links between seemingly disparate sources of information was to make all of the sources readily available. Once the information was at hand, then the mind would have an easier time drawing the connecting lines between the points.
Initial Sketches
The first sketches here show the ideation process about the overall concept of how to surface other ‘nodes’ in the knowledge graph.
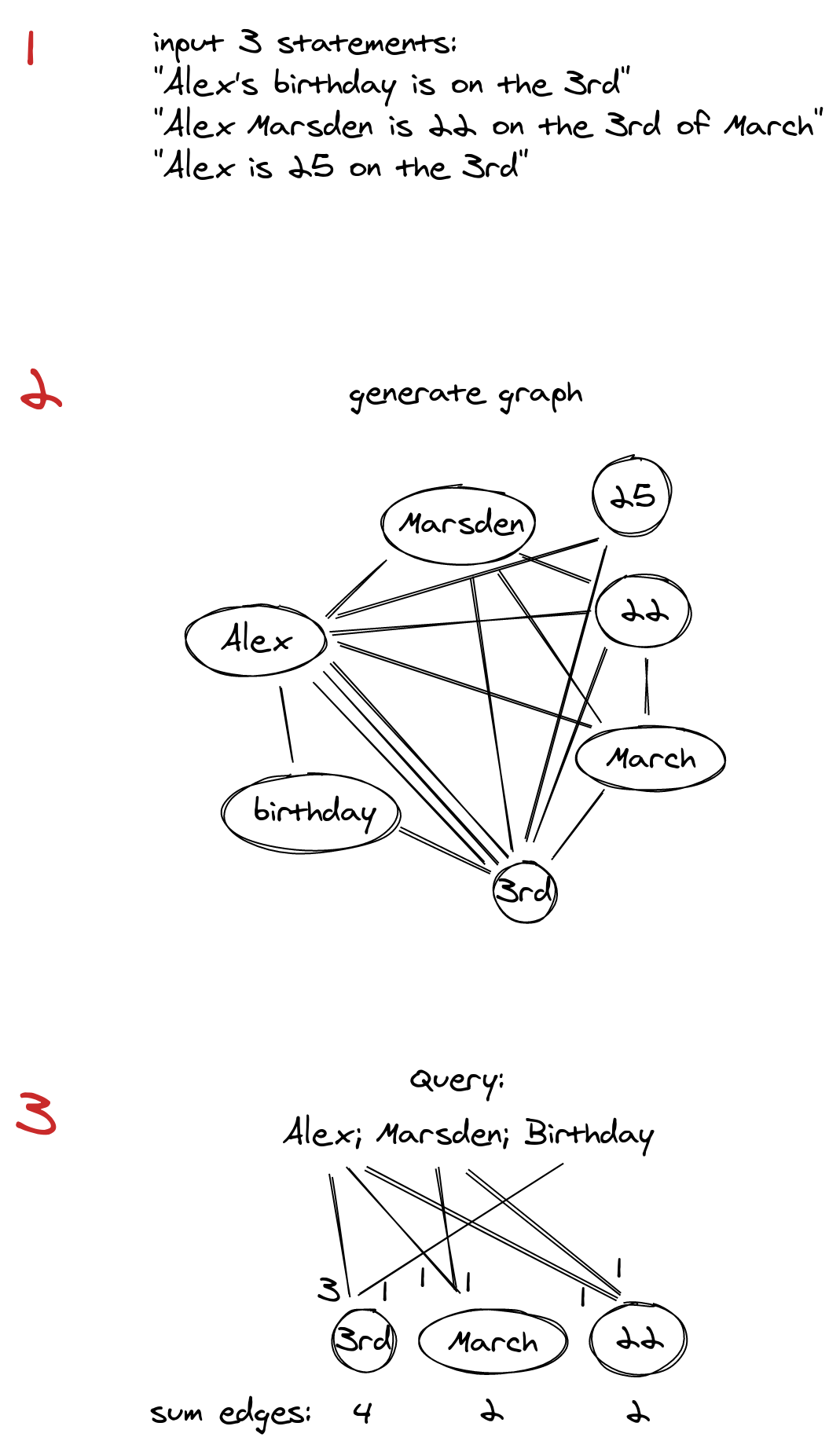
What is also clear about our brains is that the strength of connections between neurons is the path to greater understanding of a problem. Along these lines, another concept grew.
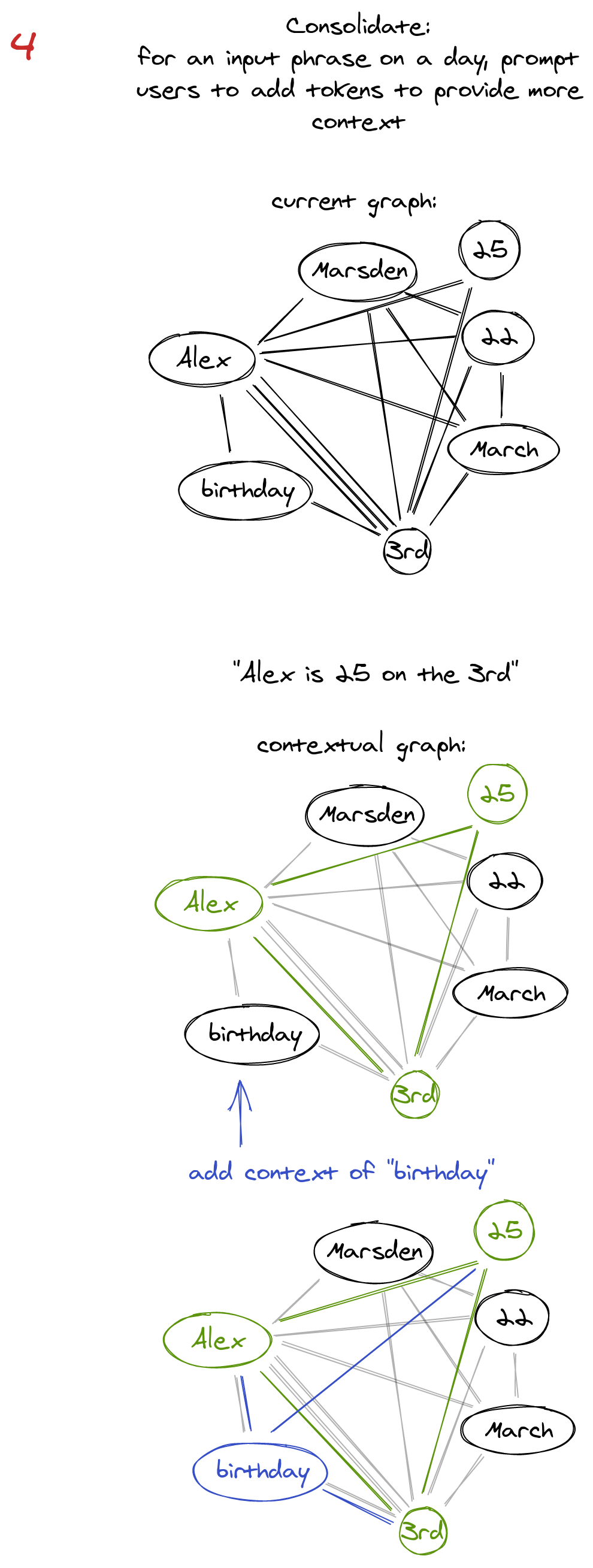
Tech Decisions
I wanted to try this out, so I had to build a prototype. There are some design principles that needed to be adhered to for it to work:
- The graph must always be available for it to act as an extended mind
- The interaction must be quick and reliable
- The tool must ingest a lot of information for it to work well, so it must be both appealing to use frequently and scaleable
In order to meet these criteria, I ended up with a few key technology choices:
- React Native for the user interface
- FastAPI for the backend
- neo4j for the database
These allow me to meet all of the design principles, as well as iterate fairly quickly. neo4j would be a new thing for me but that’s interesting in itself.
Building the prototype
Building the first version took a few days of solid effort. But it now lives on my phone!
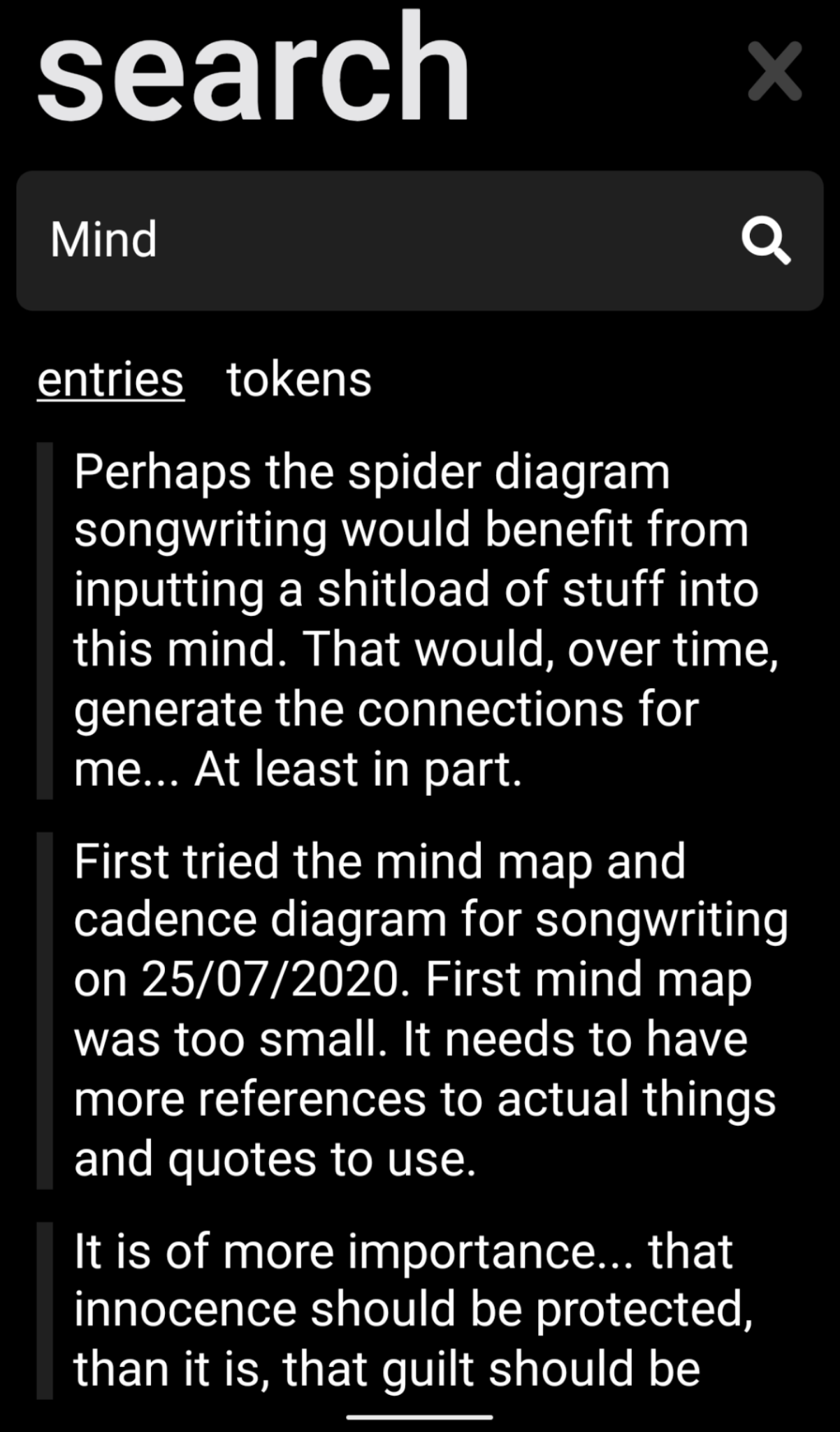
You can see that the interface shows entries that you have made, along with tokens that represent the nodes of the graph (lemmatized versions of the input words). You can also easily add new entries in another screen.
The backend runs in a small droplet on Digital Ocean for about $5/mo. Both the database and the server run in a docker-compose network fronted by traefik. This is cheap enough that it’s not breaking the bank and easy enough to manage by simply SSHing into the droplet, pulling the latest images and restarting the containers.
A few weeks of use
After a few weeks of using this tool, I’ve learnt a lot about the shortcomings and successes of the format. Here’s the graph as it stands after the first few weeks.
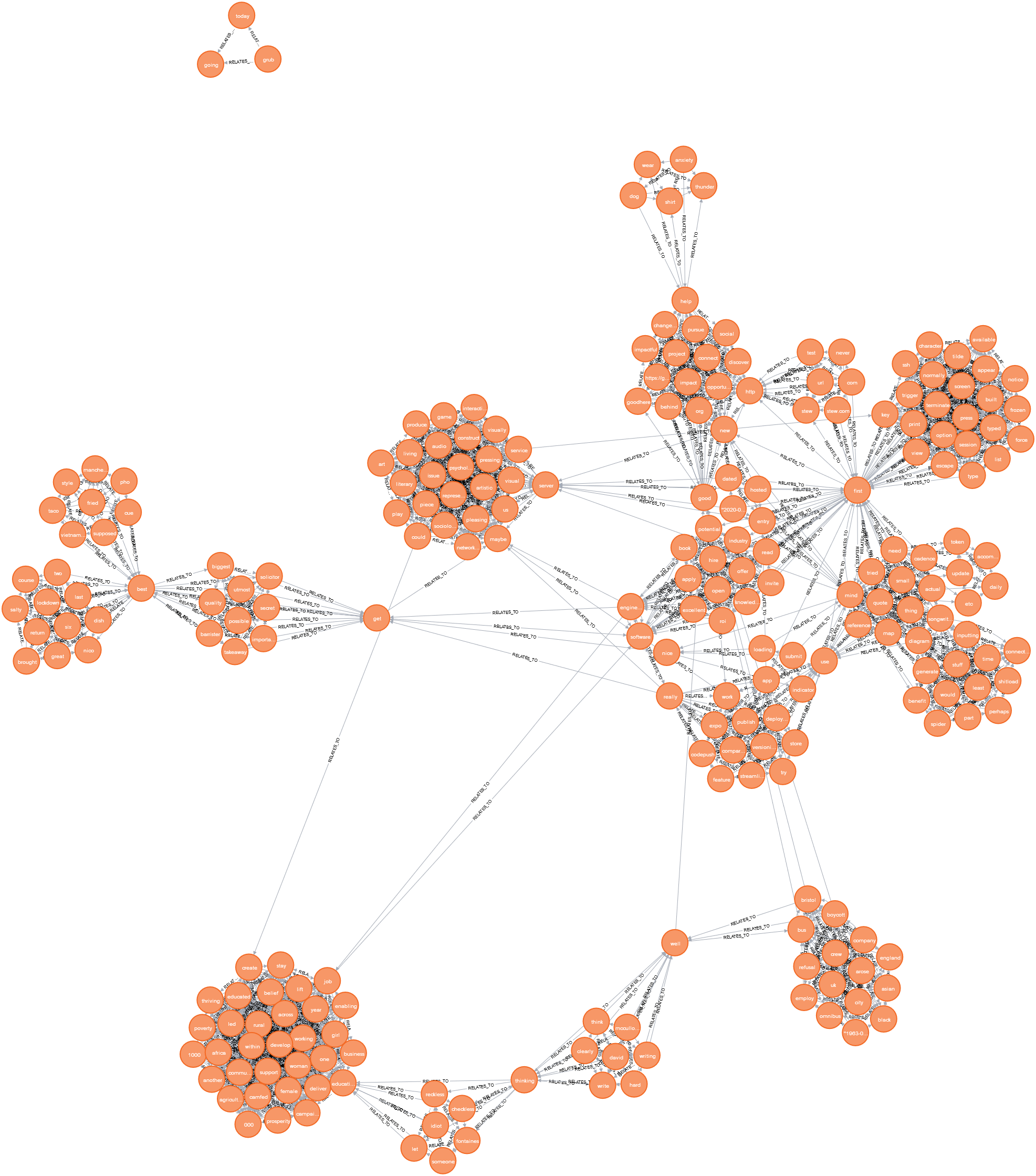
Findings
It’s hard to sanitise input
Boy, did I underestimate the effort of what is essentially an NLP problem. Parsing unstructured input into useful nodes in the graph is difficult. The more that I thought about useful atomic entities that have meaning as one node in the graph, the more complicated it got. Some simple examples here are: parsing numbers (with or without spaces, commas, decimals etc.), parsing URLs, parsing dates.
neo4j is not mature for python
I take for granted many of the database tools that I use in my day-to-day life of SQL transactions. They basically just work. neo4j with python is not like that. The client is decent but integrates with type hints poorly and has strange semantics for executing queries that still need to be worked out.
It takes a lot of input
It was clear that there needed to be a lot of input into the graph for it to be useful. I underestimated how much. Despite using it quite a lot for a large range of different thoughts, there are still clear gaps in the graph that need to be filled.
My ranking algorithm needs work
Version 0.1 implements a simple ‘if there are more connections between things then the weight goes up’. Something that I didn’t account for is the unfair advantage that is provided to words in longer entries. Simply by being present in a long stream of words, all the other words gain weight in the graph. This is not true for short entries.
Up next
Despite all of this, I still think there’s an interesting thread to be pulled at here. I’m going to continue to add to the graph and improve the tools slowly but surely.
There are so many tools in this space already, especially with Roam offering API access soon, that this might become a bit redundant!